| 【“工业大数据预测”系列】 | 您所在的位置:网站首页 › python 控制系统数字仿真 › 【“工业大数据预测”系列】 |
【“工业大数据预测”系列】
|
文章目录
前言1 数据来源2 数据预处理2.1 无效数据处理2.2 异常数据处理
3 数据预处理完整代码
前言
Hi,久等了,这里是工业大数据预测系列的第二篇。 前面我们提到,工业大数据具有诸多价值,实现工业建模、预测、控制、决策、优化、故障诊断等一系列应用。但工业界追求稳定可靠的目标使得上述应用对数据质量提出较高要求。 具体而言,工业过程中产生的数据由于传感器故障、人为操作因素、系统误差、多异构数据源、网络传输乱序等因素极易出现噪声、缺失值、数据不一致的情况,直接用于数据分析会对模型的精度和可靠性产生严重的负面影响。因此在建模前,往往需要对数据进行预处理,消除数据中的噪声、纠正不一致、识别和删除离群数据来提高模型鲁棒性,防止模型过拟合。 1 数据来源我们以2010年PHM协会(Prognostics Health Management Society)刀具磨损预测数据集来完成工业大数据预测系列文章。数据集共包含了C1 -C6共6份数据,C1、C4、C6为训练集、C2、C3、C5为测试集。每份数据共315个样本,每条样本由7个通道数据组成,所有数据均通过一台高速数控机床在铣削作业下采集获得。 文末扫码关注公众号后回复“2010PHM”获取数据集下载链接。
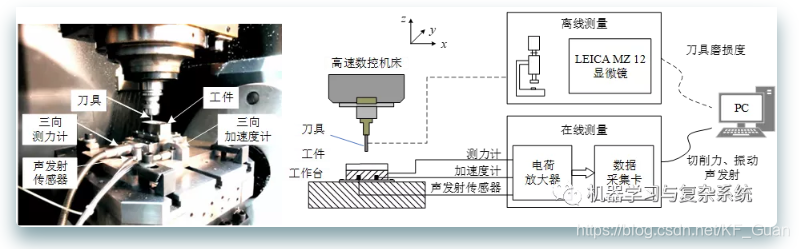
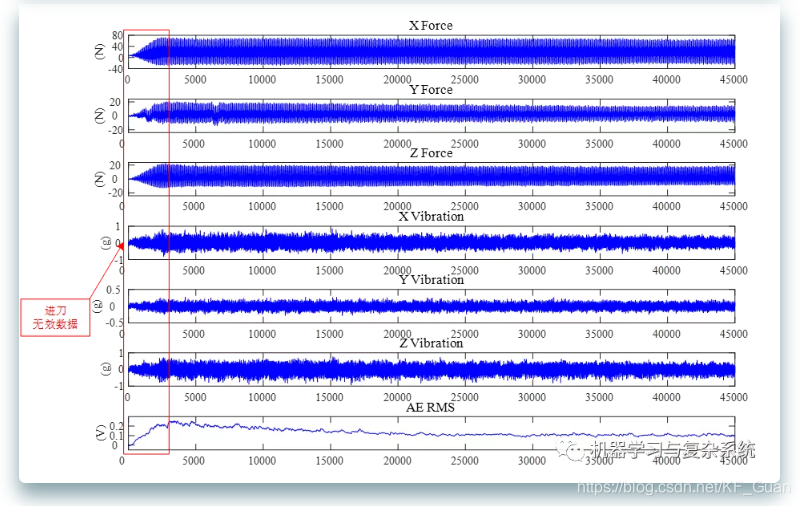
数控机床作业参数说明如下:铣刀主轴转速为10400rpm;x方向的进给速率为1555mm/min;y方向的径向切削深度为0.125mm;z方向的轴向切削深度为0.2mm。 为了获得高速数控机床作业过程的在线数据,在工件和加工平台之间安装了Kistler公司的3向平台测力计,在加工平台上固定Kistler公司的3向振动传感器,在靠近工件的位置安装声发射传感器,声发射信号主要由于材料内部结构变化造成材料内应力突变引发的弹性波产生而来的;采用Kistler5019A多通道电荷放大器和DAQ NI PCI1200数据采集卡放大和采集加工过程三个方向(x、y、z)的切削力和振动以及声发射信号;各信号的采样频率为50kHz。 因此,传感器数据由7个通道组成:x、y、z方向的铣削力、x、y、z方向的振动和声发射信号。在完成每个工件表面的铣削后,用LEICA MZ12显微镜离线测量铣刀三个刀面的磨损情况作为每个样本的标签。 csv文件的列描述第1列x轴铣削力(N)信号第2列y轴铣削力(N)信号第3列z轴铣削力(N)信号第4列x轴振动(g)信号第5列y轴振动(g)信号第6列z轴振动(g)信号第7列声发射信号(AE-RMS(V)) 2 数据预处理在该数据集中,通过对数据样本进行抽样并可视化可以发现数据缺陷主要有无效数据、异常数据两类,其中无效数据具体为进刀无效数据和退刀无效数据,异常数据为因某种原因导致的跳变数值。因此,所涉及到的数据预处理技术一般有缺失值和异常值处理等。
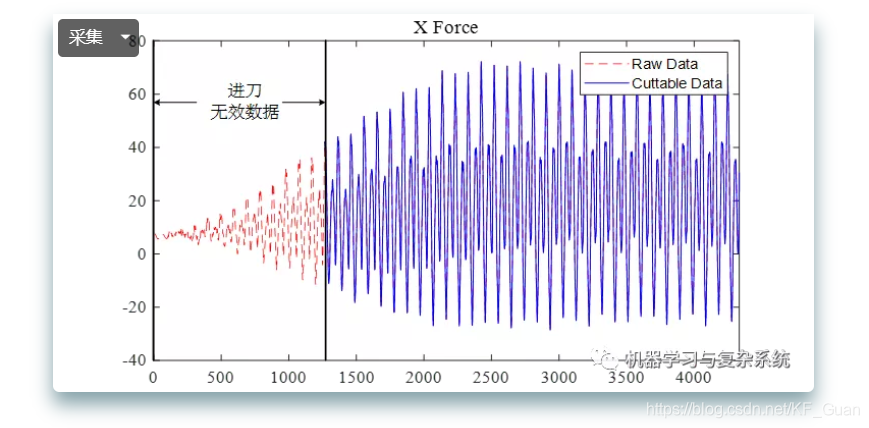
根据数据量大小和具体工业应用场景可以分为以下两类处理方式: 直接删除:适合数据量足够大而缺失的数据占比较小的情况 平滑插值填补:当样本数据较少时则可以采用平滑插值填补法,具体有线性插值法、拉格朗日插值法等。 由于数据采集的频率较高,铣削加工过程的数据点较多,每个样本达到了20余万个数据,因此可以采用直接删除的方法。 那么如何定位到删除点呢?我们可以采用一个简单的第三四分位数法。具体为:首先计算铣削过程所采集数据的第三四分位数Q3作为进退刀无效数据的临界值;然后从数据第一个值起,依次向后比较过程数据,直到出现第一个大于Q3的数值,记下当前位置,然后截断第一个值至该位置的数据;退刀无效数据则从最后一个值向前比较。 通过该方法截断的数据如图所示,图中是C1数据集第225个样本Z Force的局部放大图,蓝色实线表示截断后的数据,红色虚线表示被截断的进刀无效数据。退刀数据截断效果与之类似,不再赘述。
针对工业环境以及数据特性的不同,异常值可以分为点异常值、波动点、集体离群值和明显噪声信号等类型。处理异常值的关键点在于判断异常值,判断异常值的方法主要有以下四种方式: 恒定阈值检测。通过人工设置数据统计特征中的最大值和最小值来检测数据,当数据波动幅值超出该最大最小值形成的区间,则判定该数据点为异常点。通常有全局阈值设置和分级阈值设置两种,其中分级阈值设置可以根据不同的阈值对应不同的操作。恒定阈值法较为简单,容易实现,但不适用于非平稳信号数据,只在平稳信号数据上有一定的效果,且灵活性较低。 分位数异常检测。该方法是一种基于统计的方法。把所有的数值从小到大排列,将全部数据等分为4部分,取25%位置上的值为上四分位值,记为Q1;50%位置上的值为中位数,记为Q2;75%位置上的值为下四分位值,记为Q3;四分位距 I Q R = Q 3 − Q 1 IQR=Q3-Q1 IQR=Q3−Q1。则异常值的判断依据为大于 Q 1 + k × I R Q Q1+k \times IRQ Q1+k×IRQ 或小于 Q 3 − K × I Q R Q3-K \times IQR Q3−K×IQR 的数值,k通常取1.5。 K-Sigma异常检测。设一个服从正态分布的数据集表示为,其中 μ \mu μ为数据集的均值,delta为数据集的标准差。若数据落在( μ − k × δ \mu - k \times \delta μ−k×δ, μ + k × δ \mu + k \times \delta μ+k×δ)范围之外,则判断数据为异常数据。可以根据不同的工业场景和时序曲线,设置合适的k值作为不同级别的异常报警。通常取k值为3。 局部异常检测。局部异常检测基于滑动窗口机制,结合K-Sigma异常检测或分位数异常检测对原始数据进行分析。局部异常检测相比较于上述3种方法,使用更加灵活、适应性更强,对异常值更为敏感。但不适用于具有突变特性的数据。 突变异常数据在某一个或几个数据点出现的数据幅值突增的跳变,表现为一个较大的数值,针对此类数据的处理需要寻找一个合适的方法,既不影响大部分正常数据又能有效检测出异常值进而处理。我们可以采用基于滑动窗口的中值滤波方法——hampel滤波。具体过程如下: 设置样本两边的样本数k,则窗口大小为2k+1,设定上下界系数 n δ n_{\delta} nδ;基于滑动窗口计算每个样本的局部标准差 x δ x_{\delta} xδ、局部估计中值 x m x_m xm;计算样本的异常值上下界: 异常值上界: u p b o u n d = x m + n δ × x δ up bound=x_m + n_{\delta} \times x_{\delta} upbound=xm+nδ×xδ 异常值下界: d o w n b o u n d = x m − n δ × x δ down bound=x_m - n_{\delta} \times x_{\delta} downbound=xm−nδ×xδ若该样本值大于异常值上界或小于异常值下界,则使用估计中值 x m x_m xm替换该样本。设置 k = 4000 k=4000 k=4000 , n δ = 3 n_{\delta}=3 nδ=3。最终滤波效果对比如图所示,红色虚线表示含有突变异常值的数据,蓝色实线表示替换异常值后的数据。可以看出,hampel滤波后,C1数据集第001样本Y Force的异常值被替换,而其他数据未受影响,曲线更加平滑,异常数据点也不明显。
至此,针对刀具磨损数据集中的原始数据进行无效数据分析及处理、异常值定位分析、数据滤波处理等,已经得到了较为干净的铣削过程数据,为下一步进行数据特征提取以及建立预测模型打下了基础。 3 数据预处理完整代码 function [pre_data,count1,count2] = CutOut_and_Filter( raw_data ) % ********************************* % 裁剪去除无效数据 % ********************************* data_length = length(raw_data); Q3 = prctile(raw_data,75); % 上四分位值 for index = 1:data_length if raw_data(index) > Q3 count_forward = index; break end end for index = 1:data_length num = data_length - index; if raw_data(num) > Q3 count_backward = num; break end end data1 = raw_data(count_forward:count_backward); % ********************************* % hampel滤波示例代码 % ********************************* [destX,outPos,xMedian,xSigma] = hampel(data1, 10000, 3); pre_data = destX; count1 = count_forward; count2 = count_backward; end C1_sample = 315; C4_sample = 315; C6_sample = 315; start_time = clock; read_Path_C1 = 'C:\Users\Kaifeng Guan\Desktop\My Tool Wear Prediction\dataset\c1\c1\c_1_'; save_Path_C1 = 'C:\Users\Kaifeng Guan\Desktop\My Tool Wear Prediction\Code\new_data\dataset1\c1\c_1_'; for i = 1:C1_sample str = num2str(i, "%03d"); fprintf("Processing C1: %s \n", str); read_path = strcat(read_Path_C1, str, ".csv"); raw_data = csvread(read_path); save_path = strcat(save_Path_C1, str); mkdir(save_path) for j = 1:7 data1 = raw_data(:, j); data2 = CutOut_and_Filter(data1); save_path1 = strcat(save_path, "\f", num2str(j), ".csv"); csvwrite(save_path1, data2) end end read_Path_C4 = 'C:\Users\Kaifeng Guan\Desktop\My Tool Wear Prediction\dataset\c4\c4\c_4_'; save_Path_C4 = 'C:\Users\Kaifeng Guan\Desktop\My Tool Wear Prediction\Code\new_data\dataset1\c4\c_4_'; for i = 1:C4_sample str = num2str(i, "%03d"); fprintf("Processing C4: %s \n", str); read_path = strcat(read_Path_C4, str, ".csv"); raw_data = csvread(read_path); save_path = strcat(save_Path_C4, str); mkdir(save_path) for j = 1:7 data1 = raw_data(:, j); data2 = CutOut_and_Filter(data1); save_path1 = strcat(save_path, "\f", num2str(j), ".csv"); csvwrite(save_path1, data2) end end read_Path_C6 = 'C:\Users\Kaifeng Guan\Desktop\My Tool Wear Prediction\dataset\c6\c6\c_6_'; save_Path_C6 = 'C:\Users\Kaifeng Guan\Desktop\My Tool Wear Prediction\Code\new_data\dataset1\c6\c_6_'; for i = 1:C6_sample str = num2str(i, "%03d"); fprintf("Processing C6: %s \n", str); read_path = strcat(read_Path_C6, str, ".csv"); raw_data = csvread(read_path); save_path = strcat(save_Path_C6, str); mkdir(save_path) for j = 1:7 data1 = raw_data(:, j); data2 = CutOut_and_Filter(data1); save_path1 = strcat(save_path, "\f", num2str(j), ".csv"); csvwrite(save_path1, data2) end end end_time = clock; etime(end_time, start_time)如果您觉得文章对您有用,请给我点个赞吧! 您的肯定是对我最大的鼓励。 |


【本文地址】